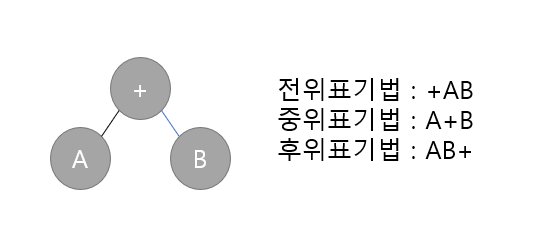
#46_불 대수의 기본 공식
- 교환법칙 : A+B=B+A, AB=BA
- 결합법칙 : A+(B+C)=(A+B)+C, A(BC)=(AB)C
- 분배법칙 : A(B+C)=AB+BC, A+BC=(A+B)(A+C)
- 멱등법칙 : A+A=A, AA=A
- 보수법칙 : A+A'=1, AA'=0
- 항등법칙 : A+0=A, A+1=1, A0=0, A1=A
- 콘센서스 : AB+BC+CA'=AB+CA', (A+B)(B+C)(C+A')=(A+B)(C+A')
- 드모르간 : A'+B'=(AB)', A'B'(A+B)'
- 복원법칙 : A'=A
#47_논리 게이트

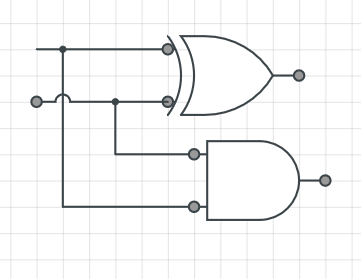
#48_반가산기(HA ; Half Adder)
- 1Bit짜리 2진수 2개를 덧셈한 합(S)과 자리올림 수(C)를 구하는 회로
0 0 1 1 A
+ 0 + 1 + 0 + 1 + B
ㅡㅡㅡ ㅡㅡㅡ ㅡㅡㅡ ㅡㅡㅡ ㅡㅡㅡ ㆍS : 합
0 0 0 1 0 1 1 0 C S ㆍC : 자리올림
- 진리표
| A | B | S | C |
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 |
- 논리식 : C=AB S=A' B+AB' = A⊕B
- 논리회로
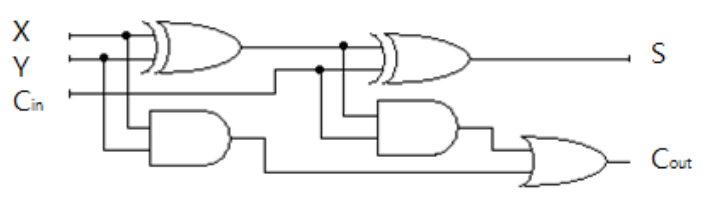
#49_전가산기(FA ; Full Adder)
- 자리 올림수(Ci)를 포함하여 1Bit 크기의 2진수 3자리를 더하여 합(S)과 자리 올림수(Ci+₁)을 구하는 회로
- 논리식
Ci+₁ = A'BCi+AB'Ci'+ABCi
= (A'B+AB')Ci+AB(Ci'+Ci)
= (A⊕B)Ci+AB <- A'B+AB'=A⊕B, Ci'+Ci=1
S = A'B'Ci+A'BCi'+AB'Ci'+ABCi
= (A'B'+AB)Ci+(A'B+AB')Ci'
= (A⊕B)'Ci+(A⊕B)Ci'
= (A⊕B)⊕Ci
- 회로(전가산기는 2개의 반가산기(HA)와 1개의 OR Gate로 구성됨)
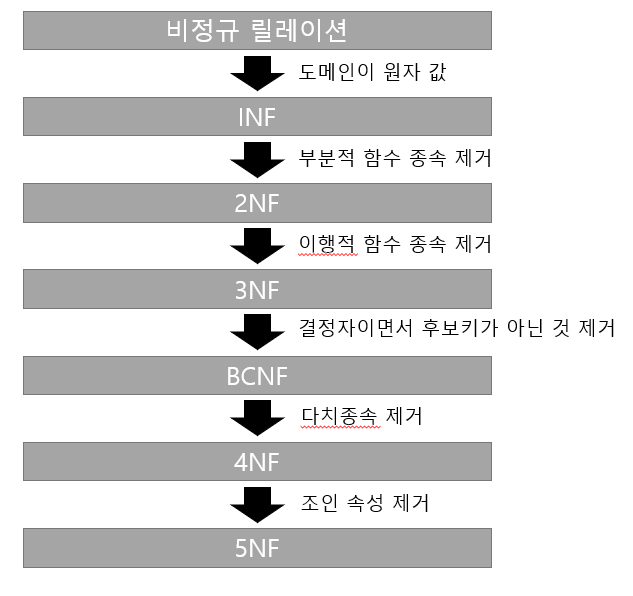
#50_자료 구성의 단위
- 비트(Bit, Binary Digit)
ㆍ자료(정보) 표현의 최소 단위
ㆍ두 가지 상태(0과 1)를 표시하는 2진수 1자리
- 니블(Nibble)
ㆍ4개의 비트가 모여 1개의 니블(Nibble)을 구성
ㆍ4비트로 구성되며 16진수 1자리를 표현하기에 적합함
- 바이트(Byte)
ㆍ문자를 표현하는 최소 단위로, 8개의 비트(Bit)가 모여 1Byte를 구성
ㆍ1Byte는 256(2의 8승)가지의 정보를 표현할 수 있음
ㆍ주소 지정의 단위로 사용
- 워드(Word)
ㆍCPU가 한번에 처리할 수 있는 명령 단위
ㆍ반워드(Half Word) : 2Byte, 풀워드(Full Word) : 4Byte, 더블워드(Double Word) : 8Byte
- 필드(Field)
ㆍ 파일 구성의 최소 단위
ㆍ의미 있는 정보를 표현하는 최소 단위
- 레코드(Record)
ㆍ하나 이상의 관련된 필드가 모여서 구성됨
ㆍ컴퓨터 내부의 자료 처리 단위로서, 일반적으로 레코드는 논리 레코드(Logical Record)를 의미함
- 블록(Block) = 물리 레코드(Physical Record)
ㆍ하나 이상의 논리 레코드가 모여서 구성됨
ㆍ각종 저장매체와의 입/출력 단위를 의미하며, 일반적으로 물리 레코드라고함
- 파일(File)
ㆍ프로그램 구성의 기본 단위로, 여러 레코드가 모여서 구성됨
- 데이터베이스(Database)
ㆍ여러 개의 관련된 파일(File)의 집합
#51_보수
- 컴퓨터가 기본적으로 수행하는 가산을 이용하여 뺄셈을 수행하기 위해 사용함
- r의 보수
ㆍ10진법에서는 10의 보수가 있고, 2진법에는 2의 보수가 있음
ㆍ보수를 구할 숫자의 자리 수만큼 0을 채우고 가장 왼쪽에 1을 추가하여 기준을 만듬
ex) 33의 10의 보수는? 33+X=100 -> X=100-33 -> X=67
10101의 2의 보수는? 10101+X=100000 -> X=100000-10101 -> X=01011
- r-1의 보수
ㆍ10진법에는 9의 보수가 있고, 2진법에서 1의 보수가 있음
ㆍ10진수 N에 대한 9의 보수는 주어진 숫자의 자리 수만큼 9를 채워 기준을 만듬
ex) 33의 9의 보수는? 33+X=99 -> X=99-33 -> X=66
ㆍ2진수 N에 대한 1의 보수는 주어진 숫자의 자리 수만큼 1을 채워 기준을 만듬
ex) 10101의 1의 보수는? 10101+X=11111 -> X=11111-10101 -> X=01010
#52_2진 연산
- 정수 값을 2진수로 변환하여 표현하는 방식
- 표현할 수 있는 범위가 작지만 연산 속도가 빠름
| 종류 | 표현방법 | 비고 |
| 부호화 절대치법(Signed Magnitude) | 양수표현에 대하여 부호 Bit의 값만 0을 1로 바꾼다 | 2가지 형태의 0 존재(+0, -0) |
| 부호화 1의 보수법(Signed 1's Complement) | 양수 표현에 대하여 1의 보수를 취함 | |
| 부호화 2의 보수법(Signed 2's Complement) | 양수 표현에 대하여 2의 보수를 취함 | 한 가지 형태의 0만 존재(+0) |
- 표현범위
| 종류 | 범위 | n=8 | n=16 | n=32 |
| 부호화 절대치법 | -2ⁿ-¹+1 ~+2ⁿ-¹-1 | -127 ~ +127 | -32767 ~ +32767 | -2³¹+1 ~ +2³¹-1 |
| 부호화 1의 보수법 | ||||
| 부호화 2의 보수법 | -2ⁿ-¹ ~+2ⁿ-¹-1 | -128 ~ +127 | -32768 ~ +32767 | -2³¹ ~ +2³¹-1 |
#53_자료의 외부적 표현(BCD, ASCII, EBCDIC)
- BCD(Binary Coded Decimal, 2진화 10진 코드)
ㆍ6bit의 코드로 IBM에서 개발
ㆍ1개의 문자를 2개의 Zone비트와 4개의 Digit 비트로 표현함
ㆍ6Bit는 2의 6승개를 표현할 수 있으므로 64개의 문자 표현 가능
ㆍ1Bit의 Parity Bit를 추가하여 7Bit로 사용함
ㆍ영문 소문자를 표현하지 못함
- ASCII 코드(American Standard Code fot Information Interchange)
ㆍ7Bit 코드로 미국 표준협회에서 개발
ㆍ1개의 문자를 3개의 Zone비트와 4개의 Digit 비트로 표현함
ㆍ2의 7승개를 표현할 수 있으므로 128개의 문자 표현 가능
ㆍ1Bit의 Parity Bit를 추가하여 8Bit로 사용함
ㆍ통신 제어용 및 마이크로컴퓨터에서 사용함
- EBCDIC(Extended BCD Interchange Code, 확장 2진화 10진 코드)
ㆍ8bit의 코드로 IBM에서 개발
ㆍ1개의 문자를 4개의 Zone비트와 4개의 Digit 비트로 표현함
ㆍ2의 8승개를 표현할 수 있으므로 256개의 문자 표현 가능
ㆍ1Bit의 Parity Bit를 추가하여 9Bit로 사용함
ㆍ대형 기종의 컴퓨터에서 사용함
#54_기타 자료의 표현
- BCD 코드 = 8421코드
ㆍ10진수 1자리의 수를 2진수 4Bit로 표현함
ㆍ4Bit의 2진수 각 Bit가 8(2³), 4(2²), 2(2¹), 1(2의 0승)의 자리값을 가지므로 8421코드 라고도함
ㆍ대표적인 가중치 코드
ㆍ문자코드인 BCD에서 Zone부분을 생략한 형태임
ㆍ10진수 입,출력이 간편함
- Excess-3 코드(3초과 코드)
ㆍBCD + 3, 즉 BCD코드에 3₁.(0011₂)을 더하여 만든 코드임
ㆍ대표적인 자보수 코드이며, 비가중치 코드임
- Gray 코드
ㆍBCD 코드의 인접하는 비트를 X-OR연산하여 만든 코드
ㆍ입출력장치, D/A변환기, 주변장치 등에서 숫자를 표현할 떄 사용
ㆍ1Bit만 변화시켜 다음 수치로 증가시키기 때문에 하드웨어적인 오류가 적음
- 패리티 검사 코드
ㆍ코드의 오류를 검사하기 위해서 데이터비트 외의 1Bit의 패리티 체크 비트를 추가하는 것으로 1Bit의 오류만 검출할 수 있음
ㆍOdd Parity : Odd 패리티는 코드에서 1인 Bit의 수가 홀수가 되도록 0이나 1을 추가함
ㆍEven Parity : OddEven 패리티는 코드에서 1인 Bit의 수가 짝수가 되도록 0이나 1을 추가함
- 해밍 코드
ㆍ오류를 스스로 검출하여 교정이 가능한 코드
ㆍ1Bit의 오류만 교정할 수 있음
ㆍ데이터 비트 외에 에러 검출 및 교정을 위한 잉여 비트가 많이 필요함
ㆍ해밍 코드 중 1, 2, 4, 8, 16 ...... 2ⁿ번째 비트는 오류 검출을 위한 패리티 비트임
#55_그레이 코드 변환
- 2진수를 Gray Code로 변환하는 방법
① 2진수의 첫번째 비트는 그대로 내려 쓴다
② 2번째 Gray Bit 부터는 변경할 2진수의 해당 번째 비트와 그 왼쪽의 비트를 XOR연산하여 씀

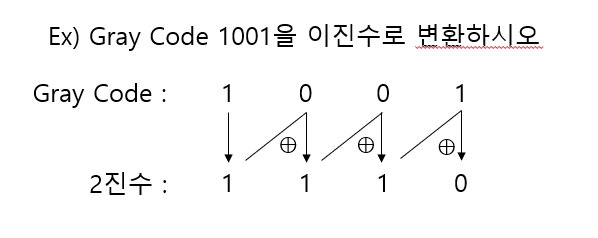
- Gray Code를 2진수로 변환하는 방법
① 그레이 코드의 첫 번째 비트는 그대로 내려쓴다
② 2번째 2진수 비트부터는 왼쪼게 구한 그레이 비트와 변경할 해당 번째 2진수 비트를 XOR연산하여 씀
#56_코드의 분류
| 분류 | 코드 종류 |
| 가중치 코드(Weight Code) | BCD(8421), 2421, 84-2-1, Biquinary(5043210), 51111, Ring-Counter(9876543210) |
| 비가중치 코드(Non-Weight Code) | 3초과(Excess-3), Gray, Jonson, 2-out-of-5, 3-out-of-5 |
| 자보수 코드(Self_Complement Code) | Excess-3, 2421, 51111, 84-2-1 |
| 오류 검출용 코드 | 해밍 코드, 패리티 검사 코드, Biquinary, Ring-Counter, 2-out-of-5, 3-out-of-5 |
'자격증 > 정보처리산업기사 - 개정전' 카테고리의 다른 글
| 정보처리산업기사 필기_2과목, 전자계산기 구조(#68~#78) (2) | 2020.04.16 |
|---|---|
| 정보처리산업기사 필기_2과목, 전자계산기 구조(#57~#67) (0) | 2020.04.16 |
| 정보처리산업기사 필기_1과목, 데이터베이스(#41~#45) (4) | 2020.04.15 |
| 정보처리산업기사 필기_1과목, 데이터베이스(#31~#40) (2) | 2020.04.15 |
| 정보처리산업기사 필기_1과목, 데이터베이스(#21~#30) (0) | 2020.04.15 |